The limits of Social Discovery
This is the second post in our continuing series on how and why The Hawaii Project recommends great books, and more broadly the key ingredients in a good discovery or recommendation system.
In our last post, we argued that the “ratings & review” model for decision making and discovery is corrupt and broken.
Today we’ll explore the limits of another common approach, Social Discovery.
Social Discovery is in use across the web. TripAdvisor will tell me if one of my friends has stayed at a hotel I might be considering. Spotify will show me a continuous stream of what music my friends are listening to. Quibb is doing interesting things with social news reading. This approach can be quite helpful — if for nothing more than a bit of reassurance that the thing in question doesn’t suck.
And yet…..
Let’s have a look at my Spotify page and what my friends are listening to.
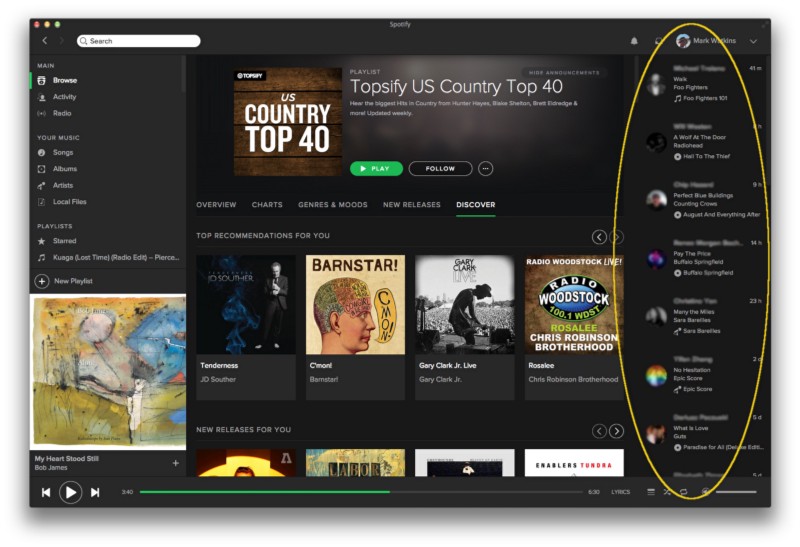
Foo Fighters (not interested). Radiohead (know all about it). Counting Crows (meh). Buffalo Springfield (nope). Sara Bareilles (nope). Epic Score (no clue who this is, and no context so I’d have to listen). Knowing what music my friends are listening to satisfies a certain voyeuristic tendency, and showing off what music I am listening to feeds my vanity and helps establish a “personal brand”. But it’s not that helpful for discovery — my friends don’t listen to the kind of music I do! (which is why Spotify leans harder on the personalized Browse feature for discovery).
What is a “discovery”? The key ingredients of a discovery are that it is personally relevant, interesting and surprising. That music above might have been interesting but it wasn’t relevant. Current discovery systems often don’t deliver on these key requirements.
In the context of book recommendations, if I read the first Game of Thrones book, Amazon’s “people who bought this also bought that” algorithm will happily tell me I should read the 2nd book in the series. Probably relevant but hardly surprising. Not a discovery. And the Goodreads model of “your friends read this so we’ll tell you about it” fails the “relevant” test. In large measure, my friends don’t read what I read.
It’s like the GEICO commercial: “Huh. did you know you can save 15% in 15 minutes?” “Everybody knows that!” (perhaps relevant but unsurprising). “well did you know the ancient pyramids were a mistake?” (the surprise). Discovery systems need to create that feeling of serendipity, creating that emotion of “wow, I never would have found that on my own”, and today’s engines often don’t.
https://youtu.be/BMoQBNIuT3M?list=PLXYlx8qRHoyJvCW78sv6wHf1eBfUrpdn5
Social discovery works when:
- my social graph and I have high alignment in interests, and/or
- the investment required to evaluate or consume is low.
Many services piggy-back their social networks off Facebook. That’s pretty much guaranteed to produce a social graph not aligned with my tastes. Just because I work with you doesn’t mean I like your movies, books or music. Quibb works because they are doing professional tech news, and the network itself is curated and piggy backs on Twitter. The graph is much more aligned to my professional news interests than my Facebook friends, and the news they read/share is therefore highly likely to be relevant. And the feed is high enough velocity the articles will likely be a surprise (that’s why they call it “news” folks — it’s new!). Further, it’s low-investment to take advantage of the articles. I just scan the headlines and click on what is interesting.
Spotify’s “social discovery” may not be highly relevant, but it does satisfy the second point — it’s low investment to taste some of that random stuff my friends listen to — I just push the play button and it’s free.
Social Discovery also requires the “velocity” of activity to be in a fairly narrow range. If the velocity is too low (I might only stay in a hotel a few times a year), the recommendations stream is too old or empty to be relevant. If the velocity is too high (say, Facebook posts), the stream rapidly becomes too big to manage and the items stop being interesting (sound like your Facebook feed?).
Lastly, socially-driven recommendations tend to be static. That recommendation for Book 2 of Game of Thrones is never going to change. If I go back to the Amazon page for Book 1 a year from now, I’ll get no new fresh insight — it’ll still be recommending Book 2 to me, although I knew that a year ago. What you want is a surprising recommendation, so if you come back a few days later you can get new ideas, and one you wouldn’t have thought of on your own.
If socially driven discovery systems have these challenges, what’s the alternative?
I am a big fan of curation. There are people (curators) who spend their time looking for interesting things and writing about them. Robert Scoble for Startups. Maria Popova for intellectual ideas and books. Jason Hirschhorn for Media. Pitchfork for Music. Aggregating their streams can produce something that is satisfies our last two requirements: that the items be interesting (because they’re curated) and surprising (because curators are always writing about something fresh and we’re aggregating those interesting items into a time-based stream that’s constantly renewed). But that aggregation won’t be sufficiently relevant. Not everything a given curator writes about will match your personal interests.
If we take those streams and layer on top of it a “picker” that grabs the personally relevant things, you will get a much more interesting, high quality stream of discoveries. I call this approach “Personalized Curation”. That is the approach we’re taking to book recommendations on The Hawaii Project, and you can see similar approaches happening in Music (Shuffler.FM and Apple Music), News (Flipboard, Quibb) and other areas.
Personally Relevant. Interesting. Surprising. Deliver on all three and you’ll get and keep your audience.
A personalized stream of Books & Articles from The Hawaii Project